Результаты
По завершению проекта представлены следующие результаты
1. оптическое распознавание текста (OCR-обработка) 20 выпусков, скачанных с сайта Российской Национальной Библиотеки (РНБ).
2. вычитка и разметка 20 томов журнала в машиночитаемом формате XML/JSON (~10 мил. слов).
3. создание и оптимизация электронной базы данных для хранения вычитанных и не-вычитанных томов.
4. добавление метаданных в базу данных, содержащих информацию о томе: номер тома, год издания, типография, редакторы, тип журнала.
5. разработка web-сайта, который теперь предоставляет пользователю следующие опции:
– Поиск по корпусу вычитанных томов на нескольких языках. Результатом выдачи является страница с запрошенным словом или фразой, а также метаданные: год публикации, номер тома, название раздела;
– Перевод найденного текста из дореформенной в современную орфографию;
– Скачивание XML-версий размеченных томов корпуса;
– Онлайн-редактирование томов (доступно после регистрации на сайте), а также сохранение результатов в базу данных;
6. создание двух версий web-сайта в более современном формате в приложении Vue на Javascript и HTML и Node.js для более удобной проработки архитектуры сайта в дальнейшем.
7. разработка программы для автоматического исправления опечаток в текстах дореформенной орфографии (спеллчекер).
8. внедрение спеллчекера на сайт цифрового архива журнала для облегчения редактирования невычитанных томов. То есть, перед тем как пользователь преступит к исправлению опечаток, наиболее частотные ошибки уже будут исправлены автоматически спеллчекером.
9. публикация в дополнительном томе сборника 27-ой международной конференции по компьютерной лингвистики "Диалог". Ссылка: http://www.dialog-21.ru/dialogue2021/results/dopmat/2021/
Корпус размеченных в XML томов журнала можно скачать в этом репозитории: https://github.com/dhhse/Otechestvennie_zapiski/tree/master/data
Презентация проекта: https://docs.google.com/presentation/d/1mBRKRz21izL9HK1eaW9a4a0OKdfRDFgcWZEcY4jZT1Y/edit?usp=sharing
Модель спеллчекера (папка model) и функция для запуска (function_for_spellchecker.py) находятся здесь: https://github.com/dhhse/Otechestvennie_zapiski/tree/master/kate_data. Данная программа позволяет исправлять опечатки в текстах дореформенной орфографии. Модель обучена на вычитанных материалах журнала "Отечественные Записки".
Скриншоты сайта:
1. Главная страница
2. Результат поиска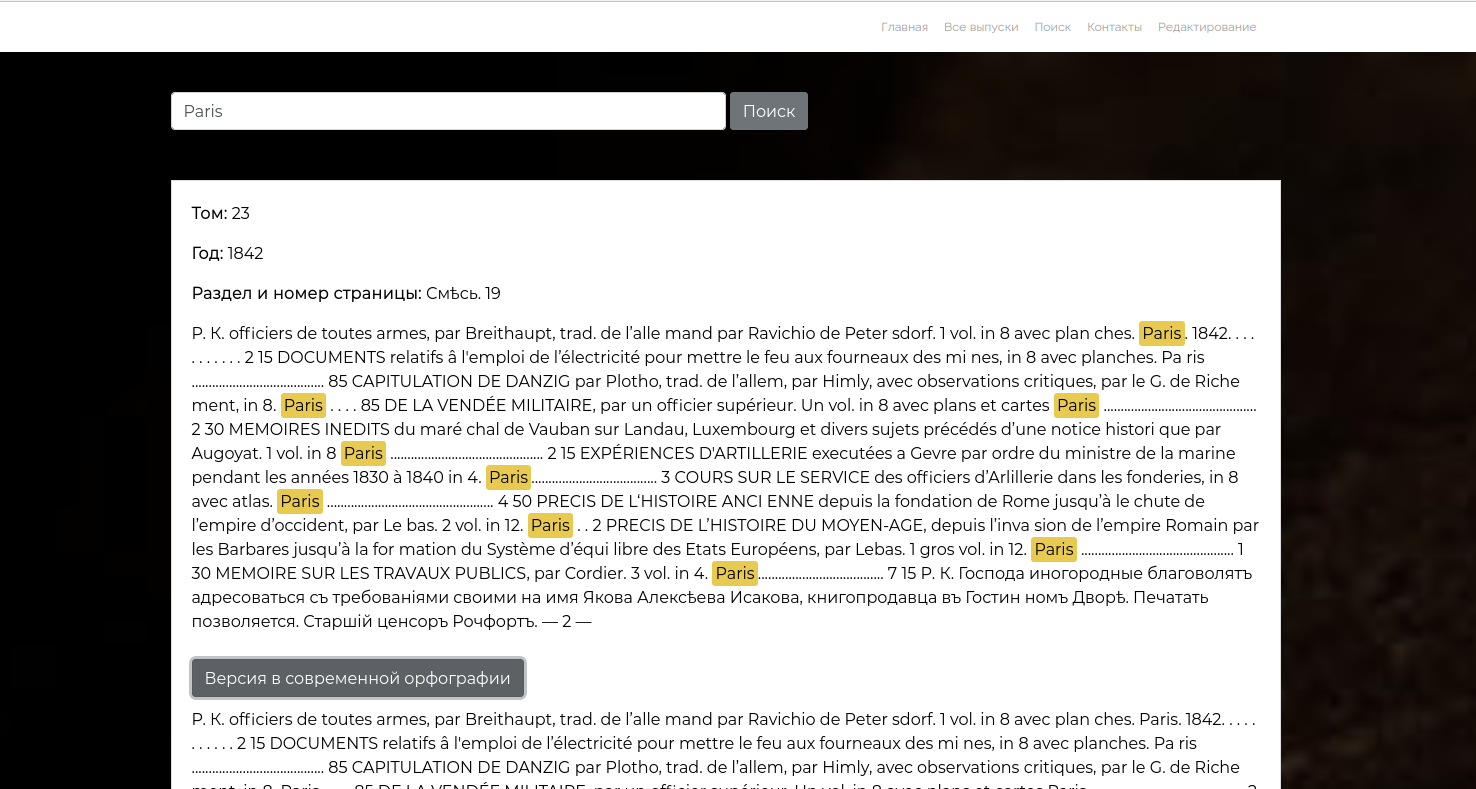
3. Корпус, аггрегированный по годам
5. Онлайн-редактирование
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.