
Отчет за второе полугодие по работе студенческого проекта "Новая шугнанская лексика"
Завершается работа над проектом «Новая шугнанская лексика и материалы для глагольной базы: шугнанские глаголы в типологическом освещении. Проект поддержки шугнанского языка». Проект создан при поддержке фонда "Гуманитарные исследования" ФГН НИУ "Высшая школа экономики" в 2022-2024 гг.
О проекте
Наш проект посвящен изучению глагольной лексики шугнанского языка. Одна из основных задач проекта: разработка и наполнение шугнанскими базы данных глагольных колексификаций. Цель данной базы – подробная разметка каждой лексемы с учетом структуры события, аргументной структуры, полисемии и семантических переходов, что в перспективе позволит делать типологические обобщения для глаголов из разных языков. В задачи проекта также входит сбор и разметка устаревшей шугнанской глагольной лексики. Проект реализуется при поддержке фонда "Гуманитарные исследования" ФГН НИУ "Высшая школа экономики" в 2023-2024 гг.
Данные и разметка
Основная задача этой базы данных – разметка и анализ глагольных колексификаций, поэтому при наполнении базы акцент делается на многозначных глаголах. Мы исследуем ограниченное число семантических областей, а именно конкретные физические события, поскольку известно, что они часто служат источником семантических переходов. Таким образом, мы начинаем с областей контакта (толкать, коснуться, ударить и т.д.), звуков (смеяться, кричать, трещать и т.д.), падения (отвалиться, обвалиться, упасть и т.д.), перемешивания (мешать, ворошить, шевелить и т.д.), и некоторые другие. Мы также стараемся включать ситуации с максимально разнообразным набором участников и структурой события.
В базе данных есть три типа данных: шаблоны, конкретные реализации и лексемы. Шаблоны – это широко понимаемые типы ситуаций, которые создаются конкретными значениями. Для каждого шаблона выделяется обобщенный набор участников и описывается структура события. Каждое конкретное значение лексемы становится отдельной реализацией более общего шаблона.
Система организована иерархически: мы описываем общие (родительские) над-шаблоны (например, “издавать звук”), на основе которых создаются более частные шаблоны (например, “смеяться”). В шаблон входят его конкретные значения, которые могут реализуются непосредственно лексемами (например, bůɣ ‘насмехаться’, шугнанский язык).
Шаблоны и конкретные значения описаны по одной и той же схеме, за исключением того, что семантические представления конкретных реализаций более конкретны и детализированы. Схема состоит из двух частей: описание участников и структуры события.
Размечаются следующие параметры:
Для участников:
- является ли участник ядерным, периферийным или инкорпорированным;
- семантическая роль участника (агенс, пациенс, инструмент и т.д.);
- таксономические характеристики участника (человек, животное, растение, часть тела, инструмент и т.д.);
- топологические характеристики (контейнер, поверхность, сфера, удлиненный объект).
Для структуры события:
-
подробно прописываются все релевантные стадии структуры события (экспозиция, начальное состояние, процесс, завершение события и т.д.);
Для каждой стадии дополнительно указывается:
- является ли стадия контролируемой;
- является ли стадия ассерцией или пресуппозицией.
Для конкретных значений также приводятся параметры, по которым они отличаются от других значений в данном шаблоне, примеры употребления и ссылка на полную словарную статью. Разные значения многозначной лексемы могут входить в разные шаблоны и различаться по составу участников и структуре события.
Ход работы
В течение учебного года команда проекта встречалась каждые две недели и обсуждала размеченные данные с Д.А.Рыжовой. Обсуждались и уточнялись параметры аннотации, дорабатывался интерфейс базы данных и способы визуализации размеченных данных.
Результаты работы (отчет за второе полугодие)
Наполнение базы данных
За второе полугодие Лея Финкельберг, Полина Леонова, Мария Суворова и Валерия Маринина внесли в базу:
- 32 новых шаблона
- 79 лексем
- 170 конкретных значений.
Таким образом, в базе есть 1007 аннотированных единиц.
Представление данных
Улучшена функция поиска по шаблонам (доступна по адресу http://lexicology.pamiri.online/search).
Ниже (илл. 2) можно увидеть как представлены результаты поиска. Результаты включают в себя все конкретные значения одного шаблона и лексемы, которыми они выражаются. Можно увидеть, какие стадии структуры события релевантны для каждого конкретного значения, а также отдельно посмотреть описание каждой стадии.
Добавлены функции построения двух типов графов:
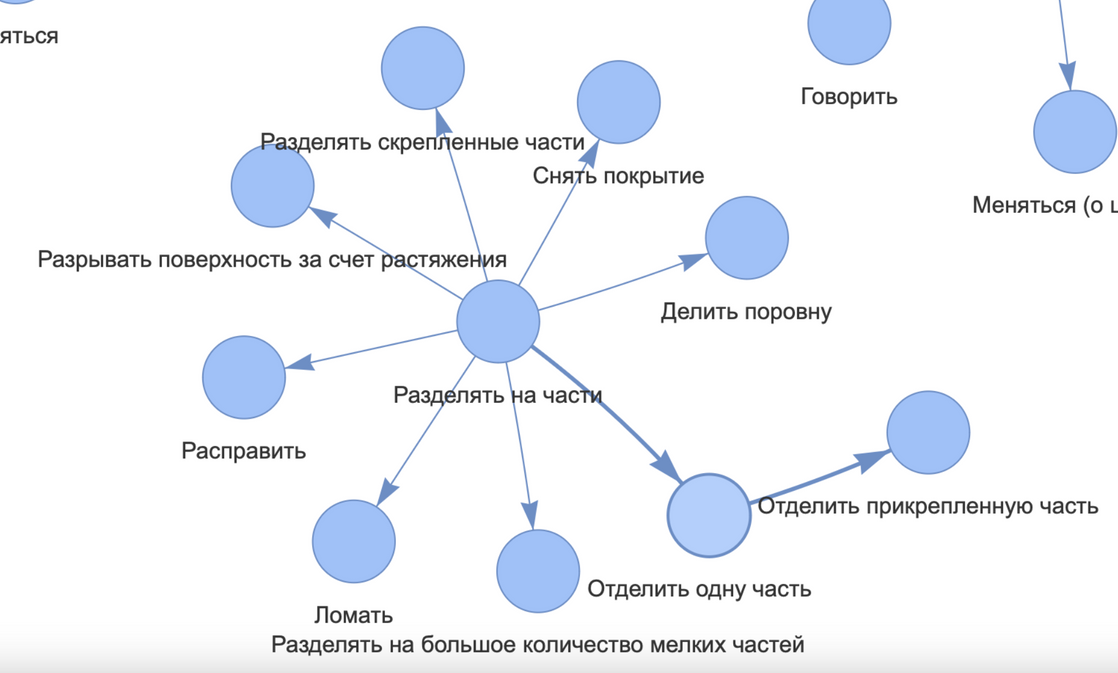
- графы, показывающие иерархический тип связи между шаблонами (какие шаблоны на основе каких были созданы, илл. 3);
- графы, отображающие наличие связывающих лексем у шаблонов.
{kind=link}
{kind=link}
Научные результаты
За время работы проекта (2022-2024) было проведено пилотное исследование нового типа лексико-семантической разметки, которая позволяет на новом уровне анализировать источники и пути глагольной колексификации через характеристики участников и структуру события. Создан и заполнен простыми шугнанскими глаголами прототип базы данных, которую в дальнейшем можно совершенствовать и пополнять данными из других языков. Аннотированные данные доступны для внешнего пользователя. Также разработаны разные типы визуализации данных при помощи графов. Представленная база данных может быть использована в качестве теоретической основы для более масштабных типологических проектов.
Участница проекта М. Суворова написала дипломную работу, в которой проанализировала 104 концепта из CLICS в формате, схожем с форматом базы в проекте, и выявила связи между колексификациями концепта и его семантикой и акциональностью. Проделанная работа позволяет дополнить базу новыми концептами и данными из разных языков, а также сопоставить данные уже внесенного шугнанского языка с типологическими данными.
Процесс и результаты работы над базой описаны в написанной, но еще не опубликованной статье “Online Database of Verbal Colexification” (Ю. Макаров, Д. Рыжова, Д. Чистякова).
![]()